|
Version |
Date |
By |
Comments |
|
0.1 |
2009/02/19 |
Ed Swartz |
initial version |
|
0.2 |
2009/06/01 |
Ed Swartz |
add sections about project model, build model, launch model |
|
0.3 |
2009/06/03 |
Ed Swartz |
add launch protocol and templates/project wizards section |
|
0.4 |
2009-06-17 |
Ed Swartz |
update for recent process launcher API changes |
Machines and Targets
Machines
SDKs and Targets
Process launching
Example uses of machine and process launcher APIs
Filesystem Mapping and Access
Project model
Project handles and build configurations
Build configuration providers
Project and builder types
Mica and product project natures
Templates and project wizards
Template model
Project wizards
Launching model
Launching architecture
Adding launch support
Launch protocols
This document describes the architecture of Mica (Maemo IDE Common Architecture). It describes the essential interfaces and concepts and also serves as a bit of a porting guide.
Mica was not designed in an ivory tower and is a real evolving framework, so chunks of documentation are missing. Watch this space for updates and ask questions on mica-devel@garage.maemo.org in the meantime! Also, consult the ESbox and PluThon sources for real-world examples of Mica usage.
Mica is intended to serve as a common basis for Eclipse-based IDEs targeting Maemo build and/or runtime environments. With the basic assumption that the development and runtime environments will be command-line based, Mica provides a set of interfaces and extension points that serve to insulate client code from build and runtime specific dependencies. You can target the local machine, a Maemo device, a sandbox (with either or both command line rewriting or file system remapping), with one piece of code.
While Mica had its roots in the ESbox project, it has no dependencies or assumptions that Scratchbox will be used. On the other hand, Mica provides the essential abstractions that allow ESbox to exist.
(Mica actually isn't all that dependent on Maemo either – the Maemo-specific functionality is in the “maemosdk” feature. Someday we may have to bite the bullet and rename the project.)
For example, Mica isolates the Make builder logic so that Make can be executed in an aribtrary way – under Scratchbox, on the host, or even on a device (though no one has seen fit to test this, due to device disk space limitations and an aversion to pain). Mica has no idea where the program will run; it calls through the interfaces ISDKTarget, IProcessLauncher, etc. to do the job. The Scratchbox support in ESbox provides the implementations of these interfaces, which create the actual command line (e.g. “/scratchbox/login ...... make”) and convert filesystem references to the project to point into the current rootstrap. This abstraction is so clean, in fact, that ESbox was ported to Windows and MacOS X, redirecting all its output through an SSH connection to a virtual machine, without any impact whatsoever on the builder.
You may ask, why use Mica if your needs are simple, such as launching locally? Well, do you really want to rewrite process launching behavior from scratch? Mica provides tested and useful utilities around the interfaces described above. Do you really want to have assumptions that all your files are on the local host, or write it twice, for local and remote usage? Mica uses the EFS filesystem abstractions in its IFileSystemAccess wrapper, allowing your code to target either. Also, do you want to rewrite support for Make, Autotools, run/debug/profile support on host and device, device flashing, string externalization, Maemo SDK platform detection, apt packge installation, Debian package creation/deployment, etc...? All of these code is built on Mica and is easily reusable.
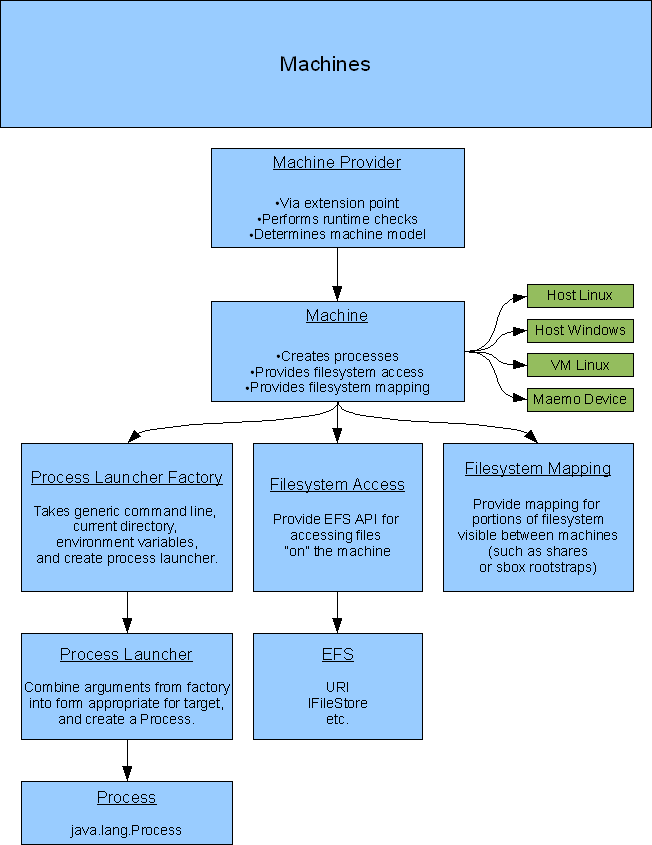
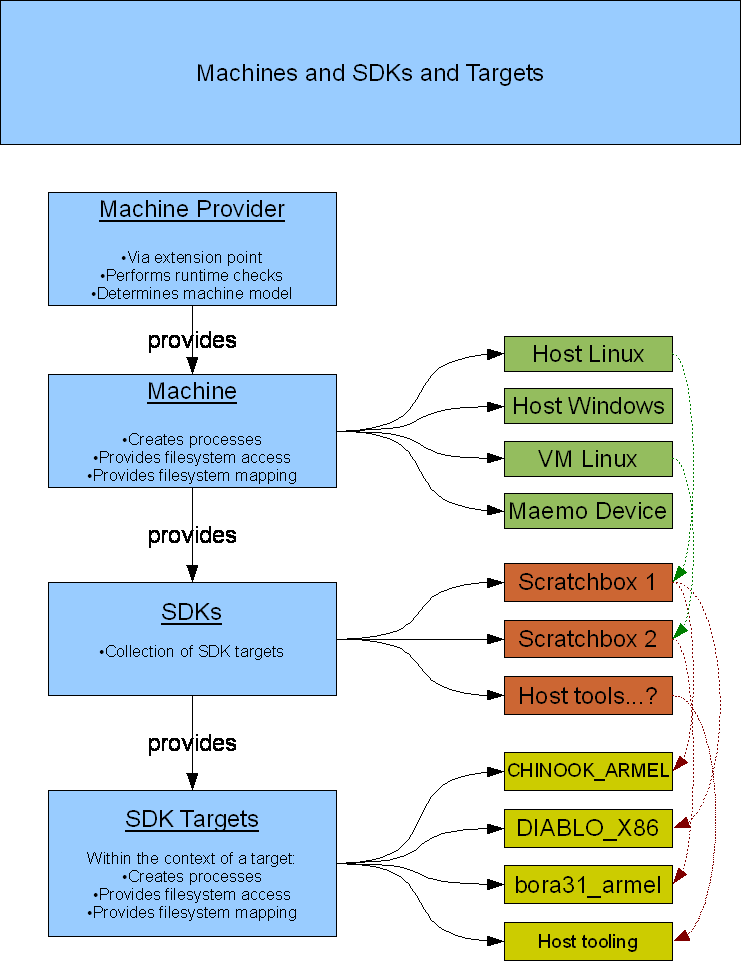
The primary architectural basis of Mica is a set of abstractions allowing a “machine” and its resources are accessed in a consistent way in order to allow tools to work the same no matter where the machine is, and also to abstract the way that SDKs and targets are defined on that machine, so that tools may be written against them in a generic way.
A machine (IMachine) is defined by:
Process creation: a simple command line like “make all” might be created, for the purpose of invoking it in scratchbox, with a command like:
/scratchbox/login -d /scratchbox/users/devel/home/devel/.esbox/ "./run.sh /home/devel/shared/workspace/myproject \\\"CWD=/home/devel/shared/workspace/cppsocketexampleproject,DBUS_SESSION_BUS_ADDRESS=unix:path=/tmp/session_bus_socket,DISPLAY=10.0.2.2:2,PWD=/home/devel/shared/workspace/myproject\\\" \\\"make all\\\""
Process launching: while Java provides a common interface for processes, there may be totally different ways to actually launch that process (locally, via SSH, over SBRSH, ...). Most Eclipse toolkits assume everything is local.
Filesystem mapping: a path like “/home/devel” might be “/scratchbox/users/devel/home/devel” under scratchbox, or may be visible on a virtual machine via a shared path like “c:\vmshare\home”. Eclipse toolkits assume file paths is literal and local (with the exception of recent spot migrations to EFS, or toolkits that are geared toward remote machines only insofar as they can be used for parallel building).
Filesystem access: the way files are accessed also differs. Generally in Eclipse, build systems must deal with both workspace resources and external files. But in ESbox, with deployment of programs to devices and the use of virtual machines in a Windows host, files may also be accessed over SSH, SBRSH, or Samba shares. Eclipse's EFS provides a suitable replacement.
Machines are provided by the IMachineFactory extension point and by the IBuildMachineFactory extension point, or by direct instantiation.
Currently, IMachineFactory extensions create SSH and SBRSH machines as well as virtual machines for QEMU and VMware. These use URIs to encode the host address, the username and password, and configuration options for the machine. You will see these used in TestMachineFactory to generate IMachine instances used for unit testing.
There is also the notion of a “host machine”, accessible via MachineRegistry#getLocalMachine().
A build machine is a specific kind of machine which allows programs to be built on it (as opposed to just being a host for launched applications).
Currently, this primarily indicates that C/C++ building is possible. Scripted languages, for instance, are assumed to not be “built”.
Build machines may provide a property page visible in ESbox > Build Machines. Currently, the only build machines are a host Linux/x86 machine (if that is the host) or a virtual machine hosting a Linux/x86 image.
Current build machines are implemented by a Linux/x86 host, if available, or one of the virtual machines.
An SDK (ISDK) is defined as an agent which can locate and provide a collection of SDK targets. Machines host SDKs.
An SDK target (ISDKTarget) is defined as a view onto a machine through another layer of process launching, filesystem mapping, and filesystem access. The primary example and driving motivation for Mica and ESbox are, of course, Scratchbox 1 and 2. While processes run on the local machine (or under a VM when cross-developing), those processes are launched with specific transformations of a general command line, and the files these processes “see” are mapped into a union of a development toolkit and a target rootstrap.
There are SDKs for Scratchbox 1 and 2, each instance of which corresponds to one installation of the respective environment. Their SDK targets correspond to the targets in Scratchbox.
Recently, we brought the Eclipse Remote System Explorer framework into Mica as a core dependency. This provides the preferred mechanism for enumerating devices like Nokia Internet Tablets. There is a single RSE SDK instance which provides RSE SDK targets for all the registered connections that match Mica's needs (currently, SSH process launching and SFTP file access).
Note, however, that generic ISSHMachine exists, and can be used to contact devices not otherwise registered through RSE.
The intent of these interfaces is to remove all the burden from client code for deciding how to launch and manage a process. You should be able to construct a generic command line, a set of environment variable changes, and a working directory, and get the same result whether you launch on the host, under Scratchbox 1 or 2, or on a remote machine.
In Mica, to launch a process, we need the command line, the environment variable changes, and the working directory.
Command line
This is the command and arguments used to launch the process on the target.
The command line is always represented as a List of Strings. Each element is one entry for argv[]. CommandLineArguments is a utility class which allows you to easily manipulate these, mainly in the uses of constructing these lists from varargs, arrays, or full command lines, if required.
Command line construction
It is never recommended to deal with full command lines (single strings). If you know what command you want to launch, take the effort to add some quotes and use the varargs forms. Look at the error waiting to happen here:
IPath myfile = ...; List<String> cmdLine = CommandLineArguments.createFromCommandLine("myprogram " + myfile.toString()); // WRONG
The issue here is, “myfile” may have spaces in it, and catenating like this will lose all information about those spaces, breaking the filepath into multiple arguments. You must always assume users will eventually have paths or filenames with spaces in them. Don't work around this with escaped quotes; just use the utilities provided:
IPath myfile = ...; List<String> cmdLine = CommandLineArguments.createFromVarArgs("myprogram", myfile.toString()); // RIGHT
Shell commands
Note that when launching a process, the first argument is an executable. At most, the process launcher might search PATH as a side effect if targeting a sandbox, but do not assume other shell semantics (like wildcard expansion, piping, I/O redirection, etc).
If you need to construct a command for a shell, the command line must be wrapped. Use CommandLineArguments#wrapCommandForUnixShell() as a convenience method to do this. This will take an existing List of Strings and construct a string, escape this, and prepend it with “/bin/sh” and “-c” arguments. Your mileage may vary, especially if you need a different shell or are not targeting a Unix-like shell.
Environment
In Mica, we work with IEnvironmentModifierBlock which is a record of the changes to make to the environment to make for a process launch – adding, changing, or removing definitions of environment variables. These are applied at process launch time.
For instance, to define CFLAGS, do:
IEnvironmentModifierBlock envBlock = ...; envBlock.define("CFLAGS", "-g -O2");
or to remove the MAKE variable from the environment:
IEnvironmentModifierBlock envBlock = ...; envBlock.undefine("MAKE");
View these as commands to apply at launch time. Unlike Java APIs, you do not work with a Properties block. This structure is biased towards local machines, where it's easy to retrieve the environment, since it's available directly from the operating system. In Mica, you can launch a program anywhere, and that environment may be expensive to retrieve (e.g. over SSH), or impossible to guess (e.g. in a sandbox whose variables may change per-launch).
If you really need to know the variables on the target, the IStandardEnvironmentProvider available from IMachine can provide this. But don't trust the data too much.
“How do I change PATH?” If you need to launch a program which may or may not be on the PATH, it's not sufficient just to modify the PATH variable; you must also prepend the program's path to the command in the command line. This is because the environment is applied for the process and is not considered when launching that process. On the other hand, you usually still want to update PATH so that program can find its own utilities or DLLs (in Windows) on the modified PATH. In Mica, use MachineUtils#adjustLaunchParametersForPATH() to do both things: (1) add an entry to PATH and (2) convert a command line to use the full path to the program if needed.
Working directory
A program may want to run in a different directory than default (usually the Eclipse workspace for local launches, or $HOME in sandboxes and remote devices). In Mica, you specify the target-relative directory when launching. Use ISDKTarget#convertHostToTargetPath() if needed.
Machines and SDK targets provide IProcessLauncherFactory instances with #getProcessLauncherFactory(), with which you construct a process launcher. The factory instance is used to create IProcessLauncher instances and to provide a starting point for modifying the environment for a launch.
If you need to modify the environment, always start with IProcessLauncherFactory#getDefaultEnvironmentModifierBlock() to get a copy of the IEnvironmentModifierBlock instance derived from the Maemo > Environment preferences. You may modify this instance by adding or removing definitions.
Then, construct a ProcessLauncherParameters block using one of the #create(...) methods in that class. A variety of forms is accepted here.
Again, avoid the “full string command line” form unless you're passing a literal string with no variable parts. Otherwise use the varargs form (e.g. “ProcessLauncherParameters.create(“foo”, myfile.toString())”) to ensure that arguments with embedded spaces are preserved and passed correctly.
The environment, if modified, must be passed or set in this parameters block. If not specified or passed as null the default environment modifier block from the factory will be used instead.
Create an IProcessLauncher from the process launcher factory using that parameter block. This launcher controls the lifetime of the process.
This process launcher is the engine for starting, monitoring, and retrieving results from a launched process. You may query the original launch parameters if needed (e.g. for logging errors).
Launch the process with #createProcess(). This asynchronously creates the process and returns a Process object appropriate for the launcher (usually a host JRE process implementation or an SSHProcess).
You may then monitor the process. You may track the Process directly, using Process APIs – but this is not recommended. It is a tricky task to properly manage external Processes, given that they may block until output is consumed, and your program will block unless output is available. Plus, you have to allow for cancellation somewhere!
Instead, for new code, queue IStreamMonitor listeners and then let an IProcessMonitor object handle the process for you.
Before launching a process, create and queue IStreamMonitor instances with IProcessLauncher#queueStreamMonitor(). These instances will incrementally receive stdout and stderr text from a process. All the stream monitors receive the same output, formatted either as blocks of raw text (for IStreamTextMonitor-derived instances) or as lines (for IStreamLineMonitor-derived instances). A monitor can have custom behavior on process creation or termination. It can also choose to interrupt the process as a whole by throwing InterruptedException in response to text it has received.
See StreamTextMonitorAdapter and StreamLineMonitorAdapter for versions that handle all the default behavior except for text processing, and various subclasses of these to collect text (StringBuilderStreamTextMonitor) or send output to a console (ConsoleStreamMonitor).
When a process is created, then you may create the IProcessMonitor instance with IProcessLauncher#createProcessMonitor(), and then monitor the process with #runBlocking() or #runNonBlocking(). You may prefer to use the ProcessLauncherUtils class to handle the monitoring step, though, since it can also handle progress monitors and cancellation.
An example of process launching:
String[] getHomeDirectoryTextListing(IMachine machine, IProgressMonitor monitor) throws MicaException {
List<String> cmdLine = CommandLineArguments.createFromVarArgs("ls", "-l");
cmdLine.add("*.txt");
cmdLine = CommandLineArguments.wrapCommandLineForShell(cmdLine); // since we use a wildcard
final IProcessLauncher processLauncher = machine.getProcessLauncherFactory().createProcessLauncher(
ProcessLauncherParameters.create(machine.getUserHome(), cmdLine));
StringBuilderStreamTextMonitor textMonitor = new StringBuilderStreamTextMonitor(false); // don't interleave
int exit = ProcessLauncherUtils.launchAndMonitorStandardStreams(
processLauncher,
new IStreamMonitor[] { new ConsoleStreamMonitor(console) },
monitor);
if (exit != 0)
throw new MicaException("Process listing failed with exit " + exit);
return textMonitor.stdout.split("\n");
}This makes use of some useful utility classes – ProcessLauncherUtils has a variety of useful shorthands for common tasks.
This example does the same but dumps output to a console:
void showHomeDirectoryTextFiles(IMachine machine, IProgressMonitor monitor) throws MicaException {
List<String> cmdLine = CommandLineArguments.createFromVarArgs("ls", "-l");
cmdLine.add("*.txt");
cmdLine = CommandLineArguments.wrapCommandLineForShell(cmdLine); // since we use a wildcard
final IProcessLauncher processLauncher = machine.getProcessLauncherFactory().createProcessLauncher(
ProcessLauncherParameters.create(machine.getUserHome(), cmdLine));
IStreamMonitor consoleMonitor = new ConsoleStreamMonitor(CoreConsoleManager.createConsole(
true, null, "System Output")); //$NON-NLS-1$
/*int exit =*/ ProcessLauncherUtils.launchAndMonitorStandardStreams(
processLauncher,
new IStreamMonitor[] { new ConsoleStreamMonitor(console) },
monitor);
if (exit != 0)
throw new MicaException("Process listing failed with exit " + exit);
}Note that the only difference is in which IStreamMonitor instance was passed. This could be even shorter, using:
ProcessLauncherUtils.queueConsoleMonitor(processLauncher,
true, null, "System Output");//$NON-NLS-1$
which creates a MessageConsole and a ConsoleStreamMonitor and queues them for you, which means no IStreamMonitor array needs to be passed.
The ProcessLauncherUtils methods do all the work of properly tracking the streams for the process, tracking the process lifetime, allowing cancellation, and allowing for arbitrary client-side handling of the streams.
A vitally important part of Mica is understanding how to reference files which may be embedded inside sandboxes (like Scratchbox targets or rootstraps) or on other machines, in a generic way that doesn't require special casing. Fortunately the APIs hide all the ugly details, but you must use them properly, or they won't help you at all :)
The filesystem mapping (IFileSystemMapping) is used to convert paths from one context to another. Such conversion maps a path for the same file, e.g., to find the local filesystem path for a file embedded in a rootstrap or for a file on another machine whose shared filesystem is mounted on the host. Any file which cannot be accessed from one context or the other cannot be mapped.
The contexts between which you convert may be on the same machine or on different machines. You must know these contexts to call the correct mapping routines.
One example is to find the location of a project in the build machine, in order to do operations on the project with commands launched on that machine. So, on Mac OS X, the project may live at “/Users/me/Public/workspace/project”, or in Windows at “c:\maemo\shared\workspace\project”, while in a Virtualbox virtual machine, it is seen at “/home/maemo/shared/workspace/project”.
For this case, use:
IMachine buildMachine; IProject project; IPath buildMachinePath = buildMachine.getFileSystemMapping().convertHostToTargetPath(project.getLocation());
This may return “null” to indicate there is no mapping.
In such machine to machine mappings, a shared folder must be configured so that the machines can see the same subtree of a filesystem. In the UI, ESbox > Build Machines > Shared Folders contains this configuration. In the APIs, IMachine#getSharedFilesystemProvider provides this information – this data is incorporated into IMachine#getFilesystemMapping().
To map a path on the other machine back to your machine, use #convertTargetToHostPath() instead.
ISDKTarget also provides access to this mapping with #getHostToMachineFileSystemMapping().
Another example is to convert from a path in a project to a path in a Scratchbox target. In a project on Linux/x86, the path may be “/home/maemo/workspace/project/file.cpp”, while under Scratchbox 1 in a virtual machine, the path to the same file is “/scratchbox/users/maemo/home/maemo/workspace/project/file.cpp”.
For this case, use:
IPath projectPath = project.getLocation().append("file.cpp"); try { IPath targetPath = sdkTarget.convertHostToTargetPath(projectPath); } catch (MicaException e) { ... }
When a build machine is inside a virtual machine, the same routine is used. The conversion first maps through the shares exposed between the host and the build machine, then maps into the target. This is why this version throws an exception (more complexity leading to different failures)... plus that's the way the existing code did it, and it was easier not to deal with nulls. :)
As an example of cross-machine mapping: an include file used by C/C++ may be “/usr/include/gtk/gtk-2.0/gtk.h” from a given Scratchbox target. But on a Windows host, this file will not be mapped unless there is a file mapping from the virtual machine's “/scratchbox” or “/home/maemo” directory to a shared drive on that host. (This is not configured by default.) If “s:\” is mapped to “/scratchbox” in the VM, then such a mapping from target to host would produce “s:\users\maemo\targets\DIABLO_ARMEL\usr\include\gtk\gtk-2.0\gtk.h”.
With Mica's architecture, we were able to easily migrate from a system where Scratchbox was hosted locally (on the same host Linux/x86 machine) to one where it is hosted “remotely” through a virtual machine running on a host Windows or MacOS X or Linux/x64 machine. This required only that there be some way to designate a virtual machine as the build machine (versus assuming it is always the host machine).
There is virtually no client code that cares what the “real” host is. But the structure of the code is vitally important. Processes and files should be handled through the APIs described above to ensure portability.
Mica provides a project model that abstracts the differences between various third-party language or project features, so that Mica features and clients can use uniform code and UI to interact with such projects.
This allows for a unified project creation wizard, project conversion wizard, Debian apt package import wizard, build configuration property page hierarchy, etc. which in themselves have little or no dependencies on specific CDT or Pydev (or whatever else) plugins.
This also allows Mica to provide custom builders and a launch framework for these projects which can operate with ISDKTarget and IMachine rather than using the default implementations that typically only work with host-only launching. Thus, if you implement ISDKTarget for a new build environment, the Mica-provided project model will support it for free.
In Mica, the core project model and UI provide a framework for accessing projects (IProjectHandle) with build configurations (IBuildConfiguration). Get project handles from the ProjectManager singleton and build configurations from the project handle.
A project handle is created from an existing Eclipse project and allows manipulating its build configurations and setting its active build configuration. Project handles encapsulate access to the vendor-specific method of manipulating the project.
A build configuration is a set of settings, such as SDK and SDK target and execution environment and project-type-specific metadata. It can map directly to a similar concept in the concrete project model (like CDT's build configurations) or to a Mica-specific build configuration model for project models that don't use configurations (like for Pydev).
A project has an active build configuration for performing builds and launches. In Mica build selection UI, the active configuration is presented in boldface. (Note: “build” configuration is a slight misnomer since it applies to more than builds...)
While a build configuration is an actual live configuration, build configuration data (IBuildConfigurationData), on the other hand, represents only the data behind a configuration. It is used to create projects, modify the configurations, and provide UI for stock configurations the user may wish to select.
Project handle and build configuration/data implementations are associated with project types (see below).
When configuring a new project or editing build configurations in an existing project, the stock Mica build configuration UI (e.g. BuildConfigSelectionUI) uses IBuildConfigurationProvider to generate a tree of build configuration data either for SDKs or for SDK targets, depending on the style of the project.
Currently there are two primary styles of configurations assigned to projects:
In Pydev projects, for example, configurations are directly based on ISDKTarget, so SDKTargetBuildConfigurationProvider provides a build configuration for each ISDKTarget child of ISDK.
In C/C++ projects, there may be several configurations per ISDKTarget, so StockTargetBuildConfigurationProvider provides a set of stock configurations, like Debug/Optimized, for each ISDKTarget child of an eligible ISDK.
The IStockBuildConfigurationProvider interface is provided by a project builder type to provide the specific build configuration data of stock configurations according to the builder. For example, Make projects usually control a build using CFLAGS, LDFLAGS, etc. environment variables. Debian Make projects, on the other hand, use the DEB_BUILD_OPTIONS environment variable to control the build.
Note: while the style of build configuration is presented here as being specific to a project type, it's up to the client-implemented wizards to provide the IBuildConfigurationProvider. This is because the project handle only cares about build configurations, not how they are generated. For example, the Debian project import wizard uses the StockTargetBuildConfigurationProvider in its build configuration tree, because the project type is not yet known before sources are extracted and analyzed.
A project is identified in Mica by a project type (IProjectType). The project type is used in various Mica project creation, conversion, and import wizards to abstract out the way that the Eclipse project will be realized as a vendor-specific project. Mica provides CDT C, CDT C++, and Pydev project types. Get access to the project types from the ProjectManager singleton.
For instance, the project type is used to determine whether a given project is a C/C++/Python project. It can detect types for currently configured projects (by nature, usually) or arbitrary file trees (by contents). It can also provide a list of build artifacts in a project from the perspective of the type (e.g. in C/C++ projects, the IBinary model objects obtained by CDT through the use of binary parsers; in Python, all *.py[w] scripts).
Also associated with a project at creation and conversion time is the project builder type (IProjectBuilderType). This identifies the build system which transforms sources into programs. Mica provides Make, Autotools, and Debian Make (e.g. debian/rules) builders. Get access to the project builder types from the ProjectManager singleton.
As with project types, the builder type can be detected in existing projects (usually by nature) and in arbitrary file trees (by identifying specific files). Project builder types can also provide information about the build artifacts expected to be generated by the builder (e.g., before a project is built). (Note: this support is not implemented for any builder types yet.)
Typically, clients should not need to write their own project types or project builder types. Configuration of specific projects should be done by project templates, adjustments to the build configuration provider, etc.
In order for Mica to provide support for ISDKTarget/IMachine based builders and launchers, it needs to add or replace its own project natures on top of vendor-specific natures. As described above, IProjectType and IProjectBuilderType handle most of this work already.
Products themselves (like ESbox, PluThon) should add their own natures, for example via AbstractProjectWizard#configureProjectConfigHandler(), to associate projects with their products for use in UI filtering. For example, the Maemo Build Configuration property page must be provided and instantiated by a product, as well as all the new project and project conversion wizards.
Thus, an ESbox C/C++ make project has these natures:
<natures>
<nature>org.eclipse.cdt.core.cnature</nature>
<nature>org.maemo.mica.cpp.project.core.cppNature</nature>
<nature>org.maemo.mica.cpp.project.core.makeNature</nature>
<nature>org.maemo.esbox.cpp.project.cppNature</nature>
</natures>
In boldface, the Mica cppNature identifies the project as “recognized by Mica” and allows the project type and handle to be created. The makeNature replaces the CDT make nature, which only builds locally. The remaining nature is used by ESbox to distinguish this project as an ESbox project.
The org.maemo.mica.common.project.core.ITemplate[Provider] interface and the org.maemo.mica.common.project.core.templateProvider extension provides the basis of an extensible model for handling templates. Currently, only project-generating templates are supported, but these can easily be used for New File or New Class (or anything else) wizards.
A template is essentially metadata plus “processing”. The implementation of “processing” is completely up to the implementor, but it should not include work handled by the a given wizard (for example, Mica's template project wizard creates and configures the project using the project type and project builder type, so the template just handles creating initial project content and validating the installation).
The provided implementation of ITemplateProvider uses the Nokia Carbide template engine (com.nokia.carbide.templatewizard and the wizardTemplate extension). In this model, a plugin publishes wizardTemplate extensions to register one or more templates. The extension includes metadata that provide most of the information in the ITemplate implementation. The actual guts of the template are in a separate directory along with a template.xml file. The template.xml file publishes a list of pages with fields which may be edited in UI, and a list of processes (implementing com.nokia.carbide.templatewizard.IProcess) which do the work of the template using the variables defined by those fields.
The Carbide template engine and Mica provide several useful Carbide template processes for generating a project, especially the sticky aspects of copying and expanding variables in a tree of sources, registering C/C++ indexer metadata, and checking the user's SDK installation for compatibility with the template (and offering to upgrade). You may provide your own ITemplateProvider and ITemplate implementations, but for ease of integration, you may want to implement a hybrid approach that combines whatever custom template expansion engine with the Carbide processes, so you can make use of pre-written support.
Mica provides a hierarchy of abstract classes useful in generating “New project” wizards. org.maemo.mica.common.project.ui.wizards.AbstractTemplateWizard is the basis of the tree, with AbstractTemplateProjectWizard built on top of that.
The AbstractTemplateProjectWizard provides complete wizard logic, showing pages with the list of templates, the initial build configurations, and integrates additional pages through the ITemplateWizardUIAdapter of ITemplate for any template-specific configuration. The wizard will create the project and configure it using the project type, builder type, and execution environment referenced in the ITemplate. All you need to do in an end-user product is implement a wizard class and provide the title, description, icon, ISDKTarget filter, and template filter.
By default, in AbstractTemplateWizard, every available template in the installation (from org.maemo.mica.common.project.core.TemplateProviderManager) is available. This is a whole lot of templates, and few of them may apply to your particular wizard. There are several levels of filtering provided to handle this.
First, the wizard will pre-filter non-project templates or templates whose published project type, builder type, or execution environment are not installed.
Then, the template selection page additionally filters templates based on platform (see ITemplate#getPlatformFilterPattern()). Since Mica is ostensibly for Maemo, the platform filter is a case-insensitive regular expression over platform names (Diablo, Fremantle, etc.). Also, the wizard implementor provides an IBuildTargetFilter to limit the supported ISDKTargets allowed for build configurations. (In practice, this is limited to “build machine” vs. “on-device” target filtering.)
Working together, these two pages provide mutual filtering so that (1) templates for unsupported platforms are not displayed and (2) targets not supported by a selected template are not displayed.
Finally, you can additionally pre-filter templates based on any of the attributes or metadata in ITemplate, or any other necessary logic. Be careful how strict your filtering is, though, and don't unnecessarily limit your wizard's power. Remember that various products may be installed together, and it may be perfectly fine for your product to use templates from another product, since other extensions to Mica are handling most of the work. For example, ESbox and PluThon wizards only exclude templates by C/C++ or Python project types.
Mica provides a unified framework for running, debugging, and profiling programs for C/C++ and Python. This is the Eclipse debug framework for launching, which is distinct from, but which uses, the Mica process launcher.
Most of the work of producing a launch consists of boringly repetitive code. Mica provides several trees of classes to make this simple. Also, of course, Mica implements these classes using the IMachine, ISDKTarget, and IFilesystemMapping/Access interfaces, ensuring that new build environments can easily be supported without rewriting.
For launch delegates, Mica provides a tree of AbstractLaunchDelegates terminating in directly usable classes for all the currently supported combinations of launches: C/C++, local/remote, and run/debug/profile. These are not intended to be extended (except where new major variations arise).
For launch configuration tab groups, Mica provides a tree rooted at AbstractMicaLaunchConfigurationTabGroup. This is a tree of abstract classes for all the currently supported combinations of launches: C/C++, local/remote, and run/debug/profile. To make a specific launch type for a product, you subclass and make a non-abstract class from the nearest abstract class. You may customize which tab groups are defined, though probably you should only add groups, not modify or remove them. You must provide an implementation of a method to create the launch shortcut instance corresponding to the launch tab group.
For launch shortcuts, Mica also provides a tree of AbstractMicaLaunchShortcut (and AbstractCppLaunchShortcut, since we need to use a CDT base class), again a tree of abstract classes, one of which you must instantiate for your needs. The shortcut provides the id of the launch configuration type created by the launch shortcut. Additionally, the shortcut implementation may provide different or extended default settings.
All launch shortcut classes implement IMicaLaunchShortcut, which has methods to configure the vendor-specific defaults, provide the launch configuration type, and provide the launch configuration's name.
In Mica, the launch shortcut takes the task of providing defaults for itself and for the launch configuration tab group. This ensures that the user experience is identical whichever path the user takes to create a configuration. (This means that if using the Run/Debug/Profile Configurations dialog, creating a new configuration may result in some dialog popups, but this is a small price to pay.)
The launch configuration name is provided through pattern expansion. Since we want to ensure that launch configurations have the same pattern, subclasses actually only provide information used to construct the name. MicaLaunchUtils#createLaunchConfigurationName actually handles this work, and subclasses override IMicaLaunchShortcut#setLaunchConfigurationNameKeys to add additional metadata keyed by MicaLaunchUtils#ELaunchConfigNameKey to a map.
Under the covers, the real Mica-dependent APIs are used in a tree of classes based on ILaunchProxy / AbstractLaunchProxy. This class hierarchy takes care of the major functional differences between launches by constructing the command lines, hooking up debuggers or backend services, etc.
The ILaunchParameterAccessor / AbstractLaunchParameterAccessor class hierarchy provides the translation between the launch configuration data and the actual paths and files used for process launching, such as the program name, configured target, the current directory, and the environment. This is intended to ease the task of testing and documenting the behavior of the various launch configuration tabs shared among this forest of launches. (For example, a “working directory” for a launch should be ISDKTarget-relative or machine-relative depending on whether it's a local or remote launch. There are some rough edges in this area, still, because we use stock UI that assumes everything is on the local filesystem, so occasionally we have to allow either a local or an ISDKTarget-relative path.)
From a client perspective, you only need to provide standard Eclipse launch configuration extensions and minimally instantiate some abstract classes.
This table shows the provided classes to be used for the respective extension points.
|
Language / Plugin |
Local Launches(current ISDKTarget performs launch): org.eclipse.debug.core.launchConfigurationTypes, org.eclipse.debug.ui.launchConfigurationTabGroups, org.eclipse.debug.ui.launchShortcuts |
Remote Launches(user chooses a download method and remote connection for launch): org.eclipse.debug.core.launchConfigurationTypes, org.eclipse.debug.ui.launchConfigurationTabGroups, org.eclipse.debug.ui.launchShortcuts |
Launch shortcut filtering recommendation Place this inside the <contextualLaunch> element for the launchShort, and in the top-level <and> block, edit the test to match your project appropriately. See below. |
|---|---|---|---|
|
CDI (old-style CDT debugger interface) |
org.maemo.mica.cpp.launch.cdi.gdb.launch: CDILocalLaunchDelegate AbstractCDILocalLaunchConfigurationTabGroup AbstractCDILocalLaunchShortcut |
org.maemo.mica.cpp.launch.cdi.gdb.launch: CDIRemoteLaunchDelegate AbstractCDIRemoteLaunchConfigurationTabGroup AbstractCDIRemoteLaunchShortcut |
<enablement>
<with variable="selection">
<count value="1"/>
<iterate>
<and>
<!-- insert product check; see below -->
<testforcePluginActivation="true" property="org.maemo.mica.cpp.isCppLaunchable"/> </and>
</iterate>
</with>
</enablement>
|
|
DSF (new-style CDT debugger interface) |
org.maemo.mica.cpp.launch.dsf.gdb.launch: DSFGDBLocalLaunchDelegate AbstractDSFGDBLocalLaunchConfigurationTabGroup AbstractDSFGDBLocalLaunchShortcut |
org.maemo.mica.cpp.launch.dsf.gdb.launch: DSFGDBRemoteLaunchDelegate AbstractDSFGDBRemoteLaunchConfigurationTabGroup AbstractDSFGDBRemoteLaunchShortcut |
(Enablement same as for CDI) |
|
C/C++ OProfile + Valgrind (note: valgrind is only "local", i.e. X86, and oprofile is only "remote", i.e. ARMEL and device) |
org.maemo.mica.cpp.launch.analysis.valgrind: ValgrindLocalLaunchDelegate |
org.maemo.mica.cpp.launch.analysis.oprofile:
|
Enablement same as for CDI/DSF, but add one of: For Valgrind: <test
forcePluginActivation="true"
property="org.maemo.mica.maemosdk.isEmulatorTarget"/>
<test
forcePluginActivation="true"
property="org.maemo.mica.maemosdk.isX86Target"/>and for OProfile: <test
forcePluginActivation="true"
property="org.maemo.mica.maemosdk.isRemoteTarget"/>
<test
forcePluginActivation="true"
property="org.maemo.mica.maemosdk.isARMELTarget"/>
|
|
Pydev |
org.maemo.mica.python.launch.local: PythonLocalLaunchDelegate Note: The shortcut has mode "profile" |
org.maemo.mica.python.launch.remote: PythonRemoteLaunchDelegate AbstractPythonRemoteLaunchConfigurationTabGroup AbstractPythonRemoteLaunchShortcut Note: The shortcut has mode "profile" |
<enablement>
<with
variable="selection">
<count
value="1">
</count>
<iterate>
<and>
<!-- insert product check; see below -->
<testforcePluginActivation="true" property="org.maemo.mica.python.isPythonLaunchable"/> </and>
</iterate>
</with>
</enablement>
|
|
Pydev OProfile + Valgrind |
org.maemo.mica.python.launch.analysis.valgrind: PythonValgrindLocalLaunchDelegate Note: The shortcut has mode "profile" |
org.maemo.mica.python.launch.analysis.oprofile: PythonOProfileRemoteLaunchDelegate AbstractPythonOProfileRemoteLaunchConfigurationTabGroup AbstractPythonOProfileRemoteLaunchShortcut Note: The shortcut has mode "profile" |
Same as for C/C++ enablement, but with org.maemo.mica.python.isPythonLaunchable |
As described above, the launch shortcuts need to have a filter so they don't show up inappropriately. The enablement checks use Mica property testers to perform the tests that apply to the basic launch configuration implementations (previously a very long series of nested and/or/test elements).
Your product should also check for a product-specific project nature so your shortcuts don't pollute unrelated projects. Note that in order for Run/Debug/Profile As... to work with file or editor selections, you cannot use the built-in Eclipse project nature check. Instead, use the Mica version, which can find the project from the current selection, for example:
<test
forcePluginActivation="true"
property="org.maemo.mica.common.hasNature"
value="org.maemo.esbox.cpp.project.cppNature">In the tables above, launches are also filtered on the kinds of targets the launch is known to work with (e.g., isX86Target, isRemoteTarget, etc). This uses the platform detected for the target of the active build configuration to make its assessment. Check the "propertyTester" extension in org.maemo.mica.maemosdk.core for a list of the properties you can test.
Also, take note of the configurationType element in the launchShortcut, as shown here in an ESbox Python Remote launch:
<!-- this maps the shortcut back to the launch configuration type,
allowing the Run/Debug Settings UI in the Resource properties view
to show associated launch configs -->
<configurationType
id="org.maemo.esbox.python.launch.remoteLaunchType">
</configurationType>For complete examples of a launch extension set, see the ESbox or PluThon *.launch plugins.
For remote run/debug/profile launches, Mica provides an extension mechanism for configuring and deploying such a launch. For example, files may be copied, directories may be mounted, packages may be built and installed, etc.
Mica uses the extensions org.maemo.mica.common.launch: launchProtocolType and launchProtocolPage to provide the “Download methods” for remote launches. These handle the model and the UI for deploying artifacts from a project to the remote device for run, debug, and profiling launches. The remote launch configuration tab groups and shortcuts automatically integrate support for selecting and initializing the launch configuration data for these protocols.
ILaunchProtocolType is the model interface. It provides the metadata to display and record the protocol type, provides the implementation of ILaunchProtocol for an actual launch, and provides support for interactively configuring a launch configuration for that type.
ILaunchProtocolPage is the UI interface. It is a simple extension of the Eclipse debug UI ILaunchConfigurationTab interface.
ILaunchProtocol is the actual engine behind the launch protocol. It handles remapping and copying files to the device, creating the IMachine that provides the process launcher, and validating the connection before launch.
Mica provides implementations for two essential protocols: SSH and SBRSH, labeled as “Copy programs (SSH)” and “Mount project (SBRSH)”.
Both will prompt the user for an RSE connection (more specifically, an IDeviceSDKTarget, which an SDK provider can create as well) through their interactive configuration methods, and use this connection name to resolve the address of the device dynamically at launch time. The launch configuration stores only the name of the connection, not the addresses. Thus, the user can edit the connection later and continue to use the same launch configuration. ILaunchProtocolType#syncLaunchParameters allows the protocol to update other parameters during a launch which (for historical or integration reasons) still rely on literal addresses.
The SSH method cooperates with the IProjectType and IProjectBuilderType to discover what files need to be copied to the device for a launch. (The user can edit the list of files in the launch configuration's “Download” page.) The SSHLaunchProtocol then generates an SSHMachine to handle launching and mapping files to the device.
The SBRSH method defaults to generating an .sbrsh configuration file automatically, which will mount the project on the device using sshfs. The org.maemo.mica.internal.api.protocol.launch.sbrsh.ISBRSHLaunchAdapter adapter provided on an ISDKTarget will provide target-specific initialization behavior. (For example, in ESbox, the “Sandbox mode” is used, substituting the target's rootstrap for the device's root directory, while this is disabled in PluThon, which doesn't use rootstraps.) Then the SBRSHLaunchProtocol generates an SBRSHMachine to handle the work of launching and mapping files to the device under an SBRSH configuration and target.